Attention 알고리즘을 단계별로 쉽게 개념적으로 알아보겠습니다:
- 기본 개념
- Attention은 입력 시퀀스의 각 요소들 간의 관련성을 계산하는 메커니즘입니다
- "모든 입력을 고려하되, 중요한 것에 더 주목한다"는 개념입니다
- 주요 구성 요소
- Query (Q): 현재 처리 중인 위치의 벡터
- Key (K): 다른 위치들의 벡터
- Value (V): 실제 정보를 담고 있는 벡터
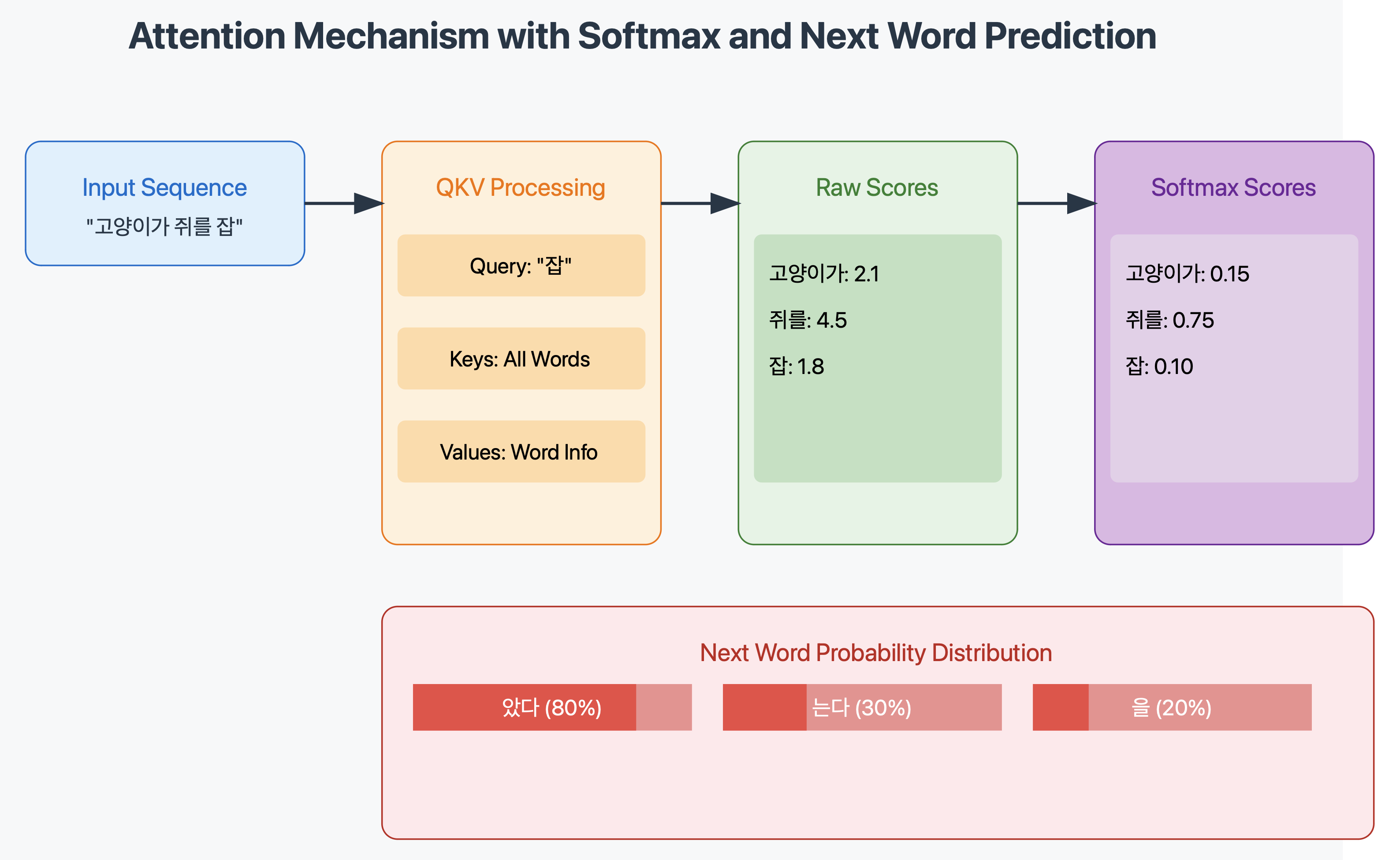
- 작동 과정 a. 각 입력 단어를 벡터로 변환 b. Query와 Key 사이의 유사도 점수 계산 c. Softmax 함수로 점수를 확률로 변환 d. 확률을 Value에 곱하여 가중치 적용 e. 가중치가 적용된 Value들을 합산
- 수식으로 표현
Attention(Q, K, V) = softmax(QK^T/√d_k)V
- d_k: 스케일링 팩터(Key의 차원)
- √d_k로 나누는 것은 점수의 분산을 조절하기 위함
- 실제 예시
문장: "고양이가 쥐를 잡았다"'쥐를' 단어의 attention 계산 시:- '고양이가'와의 관련성- '잡았다'와의 관련성 을 계산하여 각 단어의 중요도를 결정
이해를 돕기 위한 직관적 설명:
- Attention은 마치 도서관에서 책을 찾는 것과 비슷합니다
- Query는 찾고자 하는 주제
- Key는 책의 제목이나 색인
- Value는 책의 실제 내용
- 찾고자 하는 주제(Query)와 가장 관련 있는 책(Key)을 찾아 그 내용(Value)을 참고하는 것입니다
Attention의 장점:
- 긴 거리의 의존성도 잘 포착
- 병렬 처리 가능
- 해석 가능성이 높음 (어떤 입력에 주목했는지 확인 가능)
이러한 Attention 메커니즘은 Transformer 아키텍처의 핵심이 되어 현대 LLM의 기반이 되었습니다.
실제 문장을 통해 Query, Key, Value의 할당을 설명해드리겠습니다.
예시 문장: "오늘 날씨가 좋아서 공원에 산책을 갔다"
1. Self-Attention에서의 Q, K, V 할당
"산책을" 단어를 중심으로 attention을 계산하는 경우:
- Query (찾고자 하는 주제)
- "산책을"이라는 단어의 벡터가 Query가 됩니다
- 이 Query를 통해 문장의 다른 부분들과의 관련성을 찾습니다
- Key (색인/참조)
- 문장의 모든 단어들이 Key가 됩니다:
- "오늘" (Key1)
- "날씨가" (Key2)
- "좋아서" (Key3)
- "공원에" (Key4)
- "산책을" (Key5)
- "갔다" (Key6)
- 문장의 모든 단어들이 Key가 됩니다:
- Value (실제 정보)
- 각 Key에 해당하는 단어들의 의미 정보가 Value가 됩니다
- Key와 동일한 단어들이지만, 다른 벡터 표현을 가집니다
2. 계산 과정 예시
Copy
1. Query("산책을")와 각 Key의 유사도 점수 계산:
- Score("오늘") = 0.1 // 관련성 낮음
- Score("날씨가") = 0.2 // 약간의 관련성
- Score("좋아서") = 0.3 // 중간 정도의 관련성
- Score("공원에") = 0.8 // 높은 관련성
- Score("산책을") = 1.0 // 자기 자신과 가장 높은 관련성
- Score("갔다") = 0.4 // 중간 정도의 관련성
2. 이 점수들을 Softmax를 통해 확률로 변환 3. 각 Value에 이 확률을 곱하여 가중합 계산
3. 실제 의미 해석
- "산책을"이라는 단어를 이해하기 위해:
- "공원에"라는 단어에 높은 가중치 → 장소 정보
- "날씨가 좋아서"라는 문맥에 중간 정도의 가중치 → 이유/상황 정보
- "갔다"라는 행동에 중간 정도의 가중치 → 행동 정보
- "오늘"이라는 시간 정보에는 낮은 가중치
4. 다른 예시 - 중의성 해소
문장: "그는 책상 위의 사과를 먹었다"
"사과를" 단어의 attention 계산:
- Query: "사과를"
- Keys: 모든 단어들
- Values: 모든 단어들의 의미 정보
이 경우:
- "먹었다"와 높은 attention 점수 → 이것이 회사 사과가 아닌 과일 사과임을 파악
- "책상"과 중간 정도의 attention → 위치 정보
- "그는"과는 낮은 attention → 주체와의 직접적 관련성은 낮음
이렇게 attention 메커니즘은 각 단어의 문맥적 의미를 파악하고, 중의성을 해소하는 데 도움을 줍니다.
powered by Claude 3.5 sonnet
(업데이트) 2024.12.5 함께 보면 정말 좋은 동영상이 있어 링크를 공유합니다.
https://youtu.be/dqoEU9Ac3ek?si=SYgdcboKG-RUP-SF
'생물.컴퓨터.통계' 카테고리의 다른 글
| Claude Project 활용 가이드 (1) : 연구, 교육, 투자 분석까지 (7) | 2024.12.08 |
|---|---|
| [AI와의 대화 - 1]초대형 언어 모델의 긴 문맥 처리 능력: Claude 3.5 Sonnet의 200K 토큰 처리 메커니즘 분석 (6) | 2024.12.03 |
| 트랜스포머 모델로 이미지 분석하기 - 최신 기술 트렌드 탐구 (1) | 2024.11.28 |
| Prompt Engineering (1) - 세가지 기본 원칙 (2) | 2024.10.18 |
| AI의 의학 도전: AI를 이용한 의사결정시스템(1) - 맞춤 약물 조정 (2) | 2024.09.22 |