1차 원고 작성: 2024-10-24
오늘은 "Hidden flaws behind expert-level accuracy of multimodal GPT-4 vision in medicine" 논문의 주요 내용을 정리하고자 합니다.
이 연구는 의료 분야에서 GPT-4V의 성능과 한계점을 심층적으로 분석한 중요한 논문입니다.
출처: Jin, Q., Chen, F., Zhou, Y. et al. Hidden flaws behind expert-level accuracy of multimodal GPT-4 vision in medicine. npj Digit. Med. 7, 190 (2024). https://doi.org/10.1038/s41746-024-01185-7
최근 연구들에 따르면 GPT-4V(GPT-4 Vision)가 의료 관련 과제에서 인간 의사들보다 우수한 성능을 보인다고 합니다. 하지만 이러한 평가들은 주로 객관식 문제의 정확도에만 초점을 맞추어 왔습니다. 이 연구는 한걸음 더 나아가 NEJM(New England Journal of Medicine) Image Challenges를 통해 GPT-4V의 다음 세 가지 측면을 종합적으로 분석했습니다:
1. 이미지 이해에 대한 근거
2. 의학 지식의 회상
3. 단계별 다중모달 추론 과정


GPT-4와 GPT-4V의 의료 분야 활용에 대한 연구 요약
- 대형 언어 모델(LLMs)의 성과: Generative Pre-trained Transformer 4 (GPT-4)와 같은 대형 언어 모델은 다양한 생의학적 작업에서 뛰어난 성과를 보였습니다. 예를 들어, 의료 증거 요약, 문헌 검색 지원, 의학 시험 문제 답변, 임상시험 환자 매칭 등의 작업에서 성과가 입증되었습니다.
- 기존 LLM의 한계: 대부분의 LLM은 **단일 모달리티(unimodal)**로, 텍스트 정보만을 활용합니다. 그러나 실제 임상 작업은 서술적 설명과 다양한 이미지 검사를 통합하는 것이 필요합니다.
- GPT-4V의 등장: OpenAI는 최근 **GPT-4 with Vision(GPT-4V)**을 출시하였습니다. 이는 최첨단 다중 모달리티 LLM으로, 이미지와 텍스트를 함께 분석할 수 있습니다.
- 파일럿 연구 결과: 초기 파일럿 연구에서는 GPT-4V가 의료 영역에서 뛰어난 성과를 보인 것으로 나타났습니다. 주로 다중 선택 의료 문제에 대한 정확도를 평가했으며, 몇몇 경우 GPT-4V는 의대생이나 의사보다 더 나은 성과를 보였습니다.
- 다중 선택 문제의 한계: 다만, 다중 선택 문제의 정확도가 GPT-4V의 실제 역량을 반영하지 않을 수 있습니다. 정답을 맞추었다고 해서 그 과정이 논리적 근거에 기반한 것이라고 보장할 수는 없습니다.
- 깊이 있는 분석 필요성: GPT-4V의 결정 과정이 임의적 추측이 아닌 타당한 근거에 기반하는지 평가하기 위해 철저한 분석이 필요합니다.
- 연구 목적: 이를 해결하기 위해, New England Journal of Medicine(NEJM) Image Challenge에서 단일 정답이 있는 207개의 다중 선택 문제를 사용하여 GPT-4V의 성능을 평가하였습니다. 연구는 모델의 다음 세 가지 능력에 중점을 두었습니다:
- 이미지 이해 Image comprehension: 모델이 제공된 환자 이미지를 설명하는 능력입니다.
- 의학 지식 회상 Recall of medical knowledge: 각 선택지와 관련된 방사선학적 특징 등 문제 해결에 필요한 의학 지식을 생성하는 능력입니다.
- 단계별 추론 Step-by-step reasoning: 이미지 이해와 의학 지식 회상을 바탕으로 다중 모달 추론을 통해 문제에 대한 답을 도출하는 능력입니다.
연구 설계 및 결과 요약
- 연구 설계: 특별히 설계된 프롬프트를 사용하여 GPT-4V에게 각 질문에 대한 논리적 근거를 별도의 섹션으로 나누어 생성하도록 요청했습니다. 이러한 방식은 관련 능력을 더 쉽게 파악할 수 있도록 돕습니다. GPT-4V의 답변은 각각 독립된 대화 세션에서 수동으로 기록되었습니다.
- 의학 분야별 분류 및 평가: 각 데이터셋의 질문은 의학 전문 분야로 분류되었으며, 해당 분야의 임상의가 이를 주석 처리하였습니다. 또한, 다양한 의학 전문 분야의 9명의 의사들이 다학제적으로 모집되어 질문에 답변하고, GPT-4V의 논리적 근거를 평가했습니다. 이들은 NEJM Image Challenge에서 제공된 정답 및 해설을 참고하여 평가를 진행했습니다. 세부 평가 지침은 Online Methods에 설명되어 있습니다.
- 평가 결과: 의사들의 성과는 두 가지 설정에서 평가되었습니다:
- 비공개 자료(closed-book) 설정: 외부 도구(예: 문헌 검색 엔진)를 사용하지 않고 평가한 설정.
- 공개 자료(open-book) 설정: 외부 리소스를 사용하여 실제 임상 환경을 반영한 설정.
- GPT-4V와 의사들의 성과 비교:
- GPT-4V는 전체적으로 81.6%의 정확도(신뢰 구간 CI: 75.7%-86.7%)를 달성하여 의사들의 정확도(77.8%, CI: 71.5%-83.3%)보다 높은 성과를 보였으나, 통계적으로 유의미한 차이는 아니었습니다.
- 공개 자료 설정에서 가장 높은 성과는 의사들이 기록했으며, 95.2%의 정확도(CI: 91.3%-97.7%)를 달성했습니다.
- 질문 난이도에 따른 성과 분석: 질문의 난이도에 따라 성과를 분석하기 위해, NEJM 웹사이트에서 사용자가 선택한 정답 비율을 기준으로 질문을 쉬운 질문(69개), 중간 난이도 질문(69개), **어려운 질문(69개)**으로 분류했습니다.
- 모든 응답자 그룹에서 쉬운 질문에 대해 열등하지 않은 성과를 보였으며, 그룹 간 유의미한 차이는 나타나지 않았습니다.
- 중간 난이도 질문에서는 GPT-4V가 의대생보다 비공개 자료 설정에서 유의미하게 우수한 성과를 보였지만, 의사들과는 유의미한 차이가 없었습니다.
- 어려운 질문에서는 공개 자료 설정의 의사들이 GPT-4V보다 유의미하게 높은 점수를 기록했습니다.
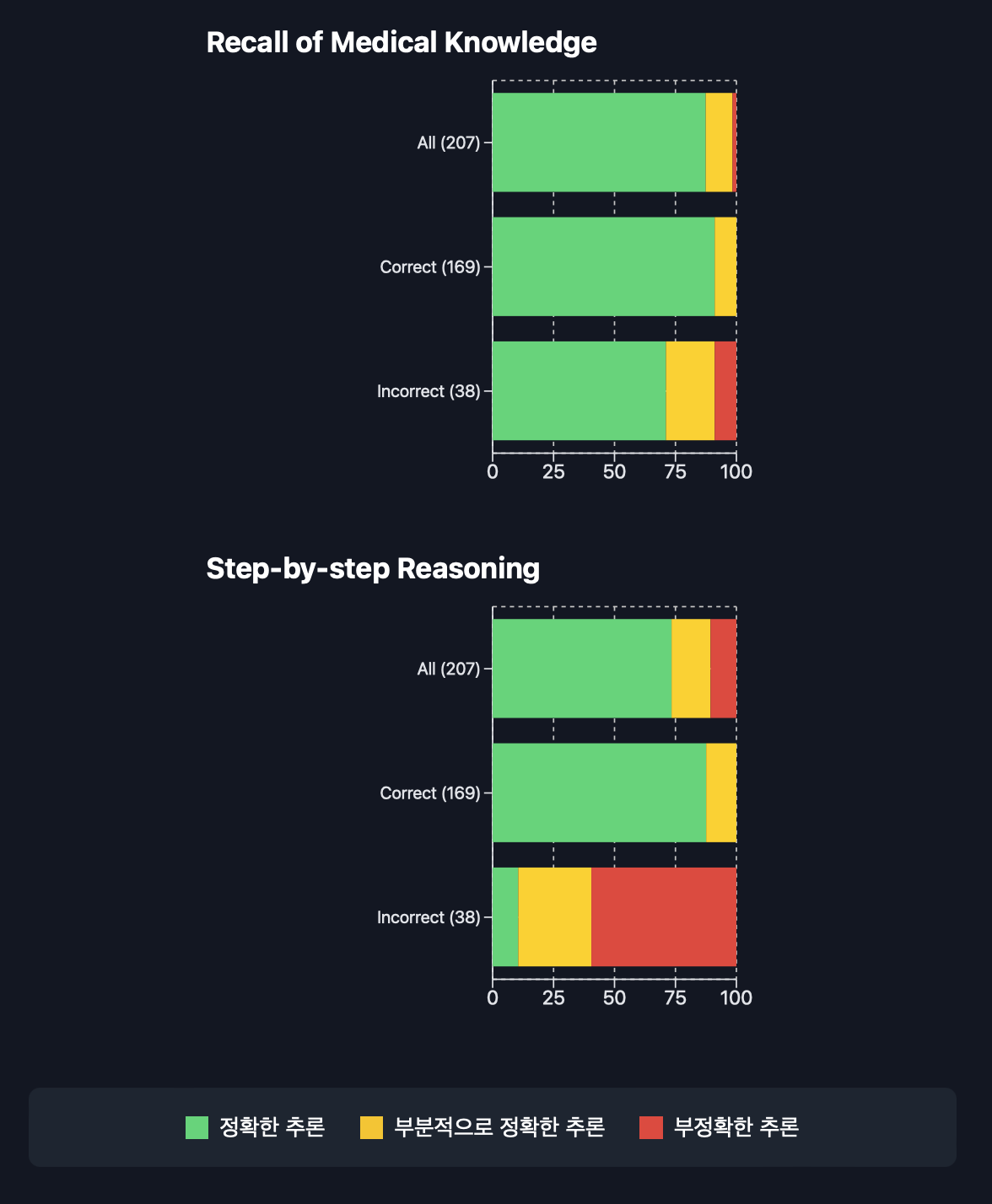
GPT-4V의 오류 분석
- GPT-4V의 오류 분석: 전체적인 성과는 만족스러웠지만, 정답을 맞췄음에도 불구하고 일부 논리적 근거가 틀린 경우가 있었습니다. 이러한 오류는 주로 이미지 이해에서 발생했으며(27.2%), **지식 회상(8.9%)**과 **추론(12.4%)**에서는 비교적 적게 발생했습니다.
결론
본 연구의 결과는 기존 연구와 일치하며, GPT-4V가 비공개 자료 설정에서 전문가 수준의 성과를 보였음을 확인할 수 있었습니다.
BiomedCLIP 성능 평가 요약
- BiomedCLIP의 평가 목적: NEJM Image Challenge 문제의 난이도를 비전-언어 기반 모델에 대해 평가하기 위해 BiomedCLIP의 성능을 테스트하였습니다. BiomedCLIP은 생의학 문헌에서 추출된 1,500만 개의 이미지-캡션 쌍으로 대조적 사전 학습을 진행한 다중 모달 언어 모델입니다.
- BiomedCLIP의 설정: BiomedCLIP은 zero-shot 설정에서 사용되었으며, 각 질문에 대한 올바른 선택지를 예측하는 방식으로 성능을 평가하였습니다. 이를 위해 Hugging Face의 microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224 모델에서 사전 학습된 이미지 인코더와 텍스트 인코더를 사용했습니다.
- 질문 구성: NEJM Image Challenge의 각 문제는 이미지와 5개의 자유 텍스트 선택지로 이루어져 있습니다. 각 선택지 앞에는 “This is an image of”라는 문구가 추가되었습니다. 질문과 선택지를 모두 결합한 방식은 결과가 좋지 않았는데, 이는 아마도 질문이 선택지보다 길이가 길기 때문인 것으로 보입니다.
- 임베딩 생성: 우리는 이미지와 각 선택지에 대해 해당 인코더를 사용하여 **임베딩(embedding)**을 생성하였으며, 이미지 표현과 각 선택지의 **내적(dot product)**을 통해 각 선택지에 대한 logit 값을 계산했습니다.
- 예측 방식: logit 값이 가장 높은 선택지가 BiomedCLIP의 예측 정답으로 선택되었습니다.
- BiomedCLIP 성능 결과: BiomedCLIP은 25.1%의 정확도를 기록하여, **확률적 예측(20%)**보다 약간 높은 성과를 보였습니다. 이는 소형 비전-언어 기반 모델에게 NEJM Image Challenge 문제의 난이도가 상당히 높음을 시사합니다.
결론
BiomedCLIP의 성능은 25.1%의 정확도로, 우연에 의한 결과보다 약간 더 높은 수준에 머물렀습니다. 이는 NEJM Image Challenge 문제의 복잡성이 현재의 소형 비전-언어 기반 모델에게 상당한 도전 과제임을 보여줍니다.
#의료AI #GPT4Vision #의료영상진단 #AI의료응용 #의료AI한계점
'의학' 카테고리의 다른 글
| B-급성 림프모구 백혈병(B-ALL)에서 CRLF2의 면역표현형 마커로서의 연관성과 유용성 (0) | 2024.11.15 |
|---|---|
| 📊 면역치료의 양날의 검: CRS의 모든 것 (1) - 발생률부터 관리까지 (0) | 2024.11.15 |
| 저항의 비밀을 풀다: 다발성 골수종에서 T세포 재지향 항체의 효과와 한계 (0) | 2024.08.09 |
| AML의 새로운 지도: 표면단백질체 분석으로 밝혀낸 맞춤형 면역치료의 미래 (0) | 2024.08.05 |
| T세포와 GPR56 발현으로 본 AML 환자의 예후: 관해인가, 재발인가? (0) | 2024.08.02 |